搜索到
6
篇与
默认分类
的结果
-
 Mongo 关联表查询 摘要Mongo支持与Mysql类似的关联表查询,但比较麻烦。通过与Mysql实现进行对比,便于理解Mongo如何实现。MysqlOrder表关联Product表的id, 实现查询订单支持搜索产品名称。# Order CREATE TABLE `order` ( `id` bigint(20) DEFAULT NULL, `no` varchar(255) DEFAULT NULL, `amount` int(11) DEFAULT NULL COMMENT '单位- 分\n', `productId` bigint(20) DEFAULT NULL, `count` int(11) DEFAULT NULL, `userId` bigint(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `order` (`id`, `no`, `amount`, `productId`, `count`, `userId`) VALUES (1, '2024062701', 10000, 1, 1, 1); INSERT INTO `order` (`id`, `no`, `amount`, `productId`, `count`, `userId`) VALUES (1, '2024062702', 20000, 1, 2, 1); # Product CREATE TABLE `product` ( `id` bigint(20) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `price` int(11) DEFAULT NULL COMMENT '单位-分' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `product` (`id`, `name`, `price`) VALUES (1, '测试产品', 10000); 关联查询查询订单、产品名称,通过left join搜索产品名称SELECT o,p.name from `order` as o left JOIN `product` as p on o.productId = p.id where p.name like '%测试%'; ## 结果 #id no amount productId count userId name 1 2024062701 10000 1 1 1 测试产品 1 2024062702 20000 1 2 1 测试产品Mongo同样在mongo中准备Order和Product的集合## insert to product db.product.insertOne({ name: '测试产品', price: 10000 }); ## result { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } ## insert to orders db.order.insertMany([ { no: '2024062701', amount: 10000, productId: "667d7fbe04cfea555206351f", count: 1, userId: 1 }, { no: '2024062702', amount: 20000, productId: "667d7fbe04cfea555206351f", count: 2, userId: 1 } ]); # result { "_id" : ObjectId("667d80b804cfea5552063520"), "no" : "2024062701", "amount" : 10000, "productId" : "667d7fbe04cfea555206351f", "count" : 1, "userId" : 1 } { "_id" : ObjectId("667d80b804cfea5552063521"), "no" : "2024062702", "amount" : 20000, "productId" : "667d7fbe04cfea555206351f", "count" : 2, "userId" : 1 }关联查询使用Mongo提供的$lookup来实现关联查询{ "$lookup": { "from": { "connectionName": "<registered-atlas-connection>", "db": "<registered-database-name>", "coll": "<atlas-collection-name>" }, "localField": "<field-in-source-messages>", "foreignField": "<field-in-from-collection>", "as": "<output-array-field>" } }那么我们使用Mongo查询,应该这样写db.order.aggregate( { $lookup: { from: "product", # 需要关联的product表 localField: "proudctId", # order中的productId foreignField: '_id', # 与proudct中的_id关联 as: "p" # product的别名,出现在查询结果中,默认是一个数组 } }, { $unwind: "$p" }, # 将p拉平,如果p是多个,那么会出现多条记录 # 此时得到 order + p:{} { $match: { "p.name": { # 过滤p.name $regex: ".*测试.*", # 使用正则,模糊查询= '%测试%' $options: "i" # 忽略大小写 } } }) 但是,没有查询到结果!?因为 在order中productId是String,而product._id是ObjectId,他俩不是同一个类型,所以是不等的。解决他俩类型不一样,那么把他俩类型弄成一样再比较!db.order.aggregate( { $lookup: { from: "product", let: { pid: "$productId" }, ## 取order.productId到变量pid中 pipeline: [ ## 在product表操作,将pid变成ObjectId后与order._id进行等于比较 { $match: { $expr: { $eq: ["$_id", { $toObjectId: "$$pid" }] } } } ], as: "p" } }, { $unwind: "$p" }, { $match: { "p.name": { $regex: ".*测试.*", $options: "i" } } }) ## Result // collection: order { "_id" : ObjectId("667d80b804cfea5552063520"), "no" : "2024062701", "amount" : 10000, "productId" : "667d7fbe04cfea555206351f", "count" : 1, "userId" : 1, "p" : { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } } // collection: order { "_id" : ObjectId("667d80b804cfea5552063521"), "no" : "2024062702", "amount" : 20000, "productId" : "667d7fbe04cfea555206351f", "count" : 2, "userId" : 1, "p" : { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } } lookup 解释1、将order.productId声明一个新的变量:pid2、将order._id与 pid比较,此时的pid转换成了obejctIdAI 解释这段代码是MongoDB聚合管道($aggregate)中的一部分,使用了$lookup阶段来实现集合之间的关联查询。这里是将当前集合(假设为订单或其他与产品相关的集合)与"product"集合进行关联,以获取与每个文档中productId字段对应的产品详细信息。我将逐步解释每一部分的含义: $lookup: 这是MongoDB聚合管道的一个操作符,用于在当前集合的文档中连接来自另一个集合的文档。它基于指定的键执行类似SQL中的左外连接。 - from: "product": 指定要连接的另一个集合名为"product"。这是你想要获取额外数据的集合。 - let: { pid: "$productId" }: 定义了一个变量pid,其值为当前文档中的productId字段。这在后续的pipeline中作为查找依据。 - pipeline: 这是一个数组,包含了在"product"集合上执行的聚合管道操作。这里仅有一个操作: - $match: 用于过滤"product"集合中的文档。它只选择那些满足特定条件的文档。 - $expr: 允许在$match中使用聚合表达式。 - $eq: 检查两个表达式是否相等。在这个例子中,检查"product"集合文档的_id字段是否等于通过$toObjectId转换后的$$pid(即来自外部文档的productId,已经转换为ObjectId类型)。 - as: "p": 指定将连接结果存储在当前文档的新字段p中,作为数组形式存在,包含匹配到的所有"product"集合的文档。 Spring Data Mongo Tempalte 实现 Pageable pageable= "Spring data Pageable'; String name= "测试" // Template不支持let,所以自己实现 AggregationOperation l = context -> new Document("$lookup", new Document("from", "product") .append("let", new Document("pid", "$projectId")) .append("pipeline", Arrays.asList( new Document("$match", new Document("$expr", new Document("$eq", Arrays.asList("$_id", new Document("$toObjectId", "$$pid")))) ) )) .append("as", "p")); UnwindOperation unwindOperation = Aggregation.unwind("p"); Criteria c = new Criteria(); if (StringUtils.isNotBlank(name)) { c.and("p.name").regex(".*" + name + ".*", "i"); } Aggregation aggregation = Aggregation.newAggregation( l, unwindOperation, Aggregation.match(c), Aggregation.count().as("c") ); Document count = MongoUtils.template(dbName).aggregate(aggregation, Order.class, Document.class) .getUniqueMappedResult(); // 没有搜索到结果,这里的count会是null if (count == null) { return PageResult.empty(); } Aggregation pageAggregation = Aggregation.newAggregation( // 这有顺序关联: 先跳过,在limit l, unwindOperation, Aggregation.match(c), Aggregation.skip(pageable.getOffset()), Aggregation.limit(pageable.getPageSize()) ); List<Order> data = MongoUtils.template(dbName).aggregate(pageAggregation, Order.class, Order.class) .getMappedResults(); return Page.of(count.getInteger("c"), data);
Mongo 关联表查询 摘要Mongo支持与Mysql类似的关联表查询,但比较麻烦。通过与Mysql实现进行对比,便于理解Mongo如何实现。MysqlOrder表关联Product表的id, 实现查询订单支持搜索产品名称。# Order CREATE TABLE `order` ( `id` bigint(20) DEFAULT NULL, `no` varchar(255) DEFAULT NULL, `amount` int(11) DEFAULT NULL COMMENT '单位- 分\n', `productId` bigint(20) DEFAULT NULL, `count` int(11) DEFAULT NULL, `userId` bigint(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `order` (`id`, `no`, `amount`, `productId`, `count`, `userId`) VALUES (1, '2024062701', 10000, 1, 1, 1); INSERT INTO `order` (`id`, `no`, `amount`, `productId`, `count`, `userId`) VALUES (1, '2024062702', 20000, 1, 2, 1); # Product CREATE TABLE `product` ( `id` bigint(20) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `price` int(11) DEFAULT NULL COMMENT '单位-分' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `product` (`id`, `name`, `price`) VALUES (1, '测试产品', 10000); 关联查询查询订单、产品名称,通过left join搜索产品名称SELECT o,p.name from `order` as o left JOIN `product` as p on o.productId = p.id where p.name like '%测试%'; ## 结果 #id no amount productId count userId name 1 2024062701 10000 1 1 1 测试产品 1 2024062702 20000 1 2 1 测试产品Mongo同样在mongo中准备Order和Product的集合## insert to product db.product.insertOne({ name: '测试产品', price: 10000 }); ## result { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } ## insert to orders db.order.insertMany([ { no: '2024062701', amount: 10000, productId: "667d7fbe04cfea555206351f", count: 1, userId: 1 }, { no: '2024062702', amount: 20000, productId: "667d7fbe04cfea555206351f", count: 2, userId: 1 } ]); # result { "_id" : ObjectId("667d80b804cfea5552063520"), "no" : "2024062701", "amount" : 10000, "productId" : "667d7fbe04cfea555206351f", "count" : 1, "userId" : 1 } { "_id" : ObjectId("667d80b804cfea5552063521"), "no" : "2024062702", "amount" : 20000, "productId" : "667d7fbe04cfea555206351f", "count" : 2, "userId" : 1 }关联查询使用Mongo提供的$lookup来实现关联查询{ "$lookup": { "from": { "connectionName": "<registered-atlas-connection>", "db": "<registered-database-name>", "coll": "<atlas-collection-name>" }, "localField": "<field-in-source-messages>", "foreignField": "<field-in-from-collection>", "as": "<output-array-field>" } }那么我们使用Mongo查询,应该这样写db.order.aggregate( { $lookup: { from: "product", # 需要关联的product表 localField: "proudctId", # order中的productId foreignField: '_id', # 与proudct中的_id关联 as: "p" # product的别名,出现在查询结果中,默认是一个数组 } }, { $unwind: "$p" }, # 将p拉平,如果p是多个,那么会出现多条记录 # 此时得到 order + p:{} { $match: { "p.name": { # 过滤p.name $regex: ".*测试.*", # 使用正则,模糊查询= '%测试%' $options: "i" # 忽略大小写 } } }) 但是,没有查询到结果!?因为 在order中productId是String,而product._id是ObjectId,他俩不是同一个类型,所以是不等的。解决他俩类型不一样,那么把他俩类型弄成一样再比较!db.order.aggregate( { $lookup: { from: "product", let: { pid: "$productId" }, ## 取order.productId到变量pid中 pipeline: [ ## 在product表操作,将pid变成ObjectId后与order._id进行等于比较 { $match: { $expr: { $eq: ["$_id", { $toObjectId: "$$pid" }] } } } ], as: "p" } }, { $unwind: "$p" }, { $match: { "p.name": { $regex: ".*测试.*", $options: "i" } } }) ## Result // collection: order { "_id" : ObjectId("667d80b804cfea5552063520"), "no" : "2024062701", "amount" : 10000, "productId" : "667d7fbe04cfea555206351f", "count" : 1, "userId" : 1, "p" : { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } } // collection: order { "_id" : ObjectId("667d80b804cfea5552063521"), "no" : "2024062702", "amount" : 20000, "productId" : "667d7fbe04cfea555206351f", "count" : 2, "userId" : 1, "p" : { "_id" : ObjectId("667d7fbe04cfea555206351f"), "name" : "测试产品", "price" : 10000 } } lookup 解释1、将order.productId声明一个新的变量:pid2、将order._id与 pid比较,此时的pid转换成了obejctIdAI 解释这段代码是MongoDB聚合管道($aggregate)中的一部分,使用了$lookup阶段来实现集合之间的关联查询。这里是将当前集合(假设为订单或其他与产品相关的集合)与"product"集合进行关联,以获取与每个文档中productId字段对应的产品详细信息。我将逐步解释每一部分的含义: $lookup: 这是MongoDB聚合管道的一个操作符,用于在当前集合的文档中连接来自另一个集合的文档。它基于指定的键执行类似SQL中的左外连接。 - from: "product": 指定要连接的另一个集合名为"product"。这是你想要获取额外数据的集合。 - let: { pid: "$productId" }: 定义了一个变量pid,其值为当前文档中的productId字段。这在后续的pipeline中作为查找依据。 - pipeline: 这是一个数组,包含了在"product"集合上执行的聚合管道操作。这里仅有一个操作: - $match: 用于过滤"product"集合中的文档。它只选择那些满足特定条件的文档。 - $expr: 允许在$match中使用聚合表达式。 - $eq: 检查两个表达式是否相等。在这个例子中,检查"product"集合文档的_id字段是否等于通过$toObjectId转换后的$$pid(即来自外部文档的productId,已经转换为ObjectId类型)。 - as: "p": 指定将连接结果存储在当前文档的新字段p中,作为数组形式存在,包含匹配到的所有"product"集合的文档。 Spring Data Mongo Tempalte 实现 Pageable pageable= "Spring data Pageable'; String name= "测试" // Template不支持let,所以自己实现 AggregationOperation l = context -> new Document("$lookup", new Document("from", "product") .append("let", new Document("pid", "$projectId")) .append("pipeline", Arrays.asList( new Document("$match", new Document("$expr", new Document("$eq", Arrays.asList("$_id", new Document("$toObjectId", "$$pid")))) ) )) .append("as", "p")); UnwindOperation unwindOperation = Aggregation.unwind("p"); Criteria c = new Criteria(); if (StringUtils.isNotBlank(name)) { c.and("p.name").regex(".*" + name + ".*", "i"); } Aggregation aggregation = Aggregation.newAggregation( l, unwindOperation, Aggregation.match(c), Aggregation.count().as("c") ); Document count = MongoUtils.template(dbName).aggregate(aggregation, Order.class, Document.class) .getUniqueMappedResult(); // 没有搜索到结果,这里的count会是null if (count == null) { return PageResult.empty(); } Aggregation pageAggregation = Aggregation.newAggregation( // 这有顺序关联: 先跳过,在limit l, unwindOperation, Aggregation.match(c), Aggregation.skip(pageable.getOffset()), Aggregation.limit(pageable.getPageSize()) ); List<Order> data = MongoUtils.template(dbName).aggregate(pageAggregation, Order.class, Order.class) .getMappedResults(); return Page.of(count.getInteger("c"), data); -
-
PromptAI - 开启交互式AI仅一步之遥! 背景我们一直从事企业服务,早在2020年通过服务国内的客户,我们就敏感的发现交互技术的变革即将发生,新的交互时代即将来临。我们把自身的专业知识、经验和能力集成到了我们的产品中,希望能帮助客户获得相应的能力,能更好的面对这个伟大的时代!PromptAI为快速对话设计和部署⽽构建的⽆代码开发环境。它基于RASA,但⼜不需要特定的RASA 知识来设计和部署聊天机器⼈。使⽤⾃然语⾔来设计⾃然语⾔对话,它最⼤限度地减少了标注和编码⼯作,旨在⼏分钟内发布企业级聊天机器⼈。有哪些特点?使用友好无需编程, 近似自然语言的方式编辑对话,能写word就能上手免费且拥有所有功能,可上线两个独立的chatbot [真-无任何费用]解决80%以上的对话需求,24小时在线服务开发友好:Web无侵入式部署,移动端完美适配FAQ、多轮、变量提取、Form、Webhook、Goto...免费下载⽣成的RASA源码ChatGPT支持私有部署 [免费版已推出,欢迎联系]适合那些用户?个人: 对chatbot/Rasa感兴趣个人开发者: 提供免费机器人服务,无任何运行及运维成本,一行代码无侵入式集成到您的应用中/小企业用户: 无需专门组建客服团队,已有客户团队的情况下极大降低客服团队工作量。其他: 欢迎联系我们获取专属解决方案.预览近似自然语言的方式编辑对话一键发布,无侵入式部署完美兼容移动端如何注册?https://www.promptai.cn联系我们:email: info@promptai.cnWechat: 官网左下角微信扫码加入群聊我们把我们产品最基本的部分贡献出来,方便企业用户开发、设计交互式对话系统,并在这个基础之上,我们提供了许多针对企业的咨询服务和解决方案。如果想更多的了解我们的产品和服务,请访问我们的网站,期待你的光临!
-
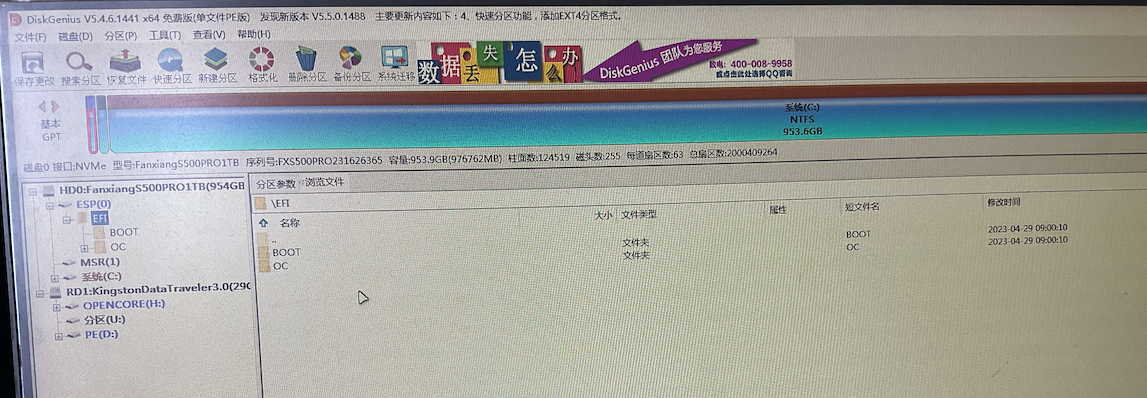
联想510s mini 安装 Ventura 背景使用联想天逸510S mini(十代 10400)安装黑苹果作为日常生产力工具。 本文参考的天逸510s Mini兼macOS BigSur安装教程,然后记录一些细节问题。配置:(仅贴出与官方配置有差异的地方)类型具体型号内存玖合(JUHOR) 48GB DDR4 3200 笔记本内存条PCIe梵想(FANXIANG)1TB SSD固态硬盘 M.2接口PCIe 4.0 x4SATA移速 金钱豹系列-256GB网卡博通BCM94360Z4准备// U盘 推荐 32 GB // Ventura 镜像 微信公众号 黑果小兵的部落阁 // Ventura 镜像刻录工具 balenaetcher https://www.balena.io/etcher // 小兵开源的EFI https://github.com/daliansky/Lenovo-TianYi-510S-Mini-Hackintosh安装修改Bios配置参考github中的信息.注:如果要关闭CPU的“CFG Lock”,需要先安装仓库中提供的BIOS版本,先进入Windows运行该程序完成BIOS版本替换(我先安装了Windows,然后进行替换,未在PE系统中测试。)制作启动U盘使用balenaetcher将下载的Ventura安装镜像刻录到U盘。 安装过程略。替换U盘中的EFI从小兵开源的EFI仓库Release页面下载最新EFI。 下载完成后,解压替换启动盘中的EFI目录。这一步必须操作,否则无法进入安装界面。注意:目前release中的版本是v2.3.0,从日志看不支持Ventura。 可以直接clone项目,然后手动拷贝EFI目录。[2023/5/3]分区将硬盘格式化为GUID分区,将在ESP分区中创建EFI文件夹,将U盘替换后的EFI拷贝进去,否则无法脱离U盘使用。 -- 这一步一定要在安装前做,实际测试安装后替换无效。安装插入U盘启动进入安装界面,选择“Install macOS Ventura”进行安装:等待一会,顺利的话会进入安装界面:首先选择“磁盘工具-Disk Utility”格式化硬盘格式为“APFS”,如果格式化失败,先格式化为“Mac OS Extended (Hournaled)”,再格式化为“APFS”.接下来退出Disk Utility,选择“Install macOs Ventura”进行安装,选中格式化好的磁盘,进行安装。安装过程会几次重启,等待即可。完成顺利的话会进入配置界面,创建用户等操作,后续即可拔掉U盘使用。总结安装过程折腾了好几天,不过好在有小兵这样的大神提供完整的EFI,减少了很多折腾的时间。非常感谢!这个机器是20年发布的到现在已三年左右,CPU已是前三代的产品。不过作为日常写写代码已满足使用,比起二手的Mac迷你仍有不小的性价比。再加上目前内存、硬盘价格非常划算,300块可买32GB内存条。 比起苹果升级太香了!这个机器购买起来比较折腾,先在淘宝买的“准系统”,然后自购CPU、内存、硬盘及网卡,整个过程还是比较有意思。目前使用下来还体验还不错,Wi-Fi、蓝牙、接力等等都可正常使用,比目前使用的15款的Macbook Pro体验好得多。说一说问题:1、使用Ipad Pro当扩展屏,拖动的时候界面不会刷新,当操作完成后才用响应。2、在SATA固态上安装的Win11,目前开机后Core0会占用100%,解决方案是拔掉所有USB,等待一会再插上去即可恢复。3、网卡天线的安装对网速、蓝牙影响,如果自购准系统,建议让卖家帮忙安装天线。其他如果你折腾这个设备遇到了问题,可以联系我提供一些帮助(如果你啥经验都没有,建议直接买成品吧)。联系我:Email: idkpengc@gmail.com文章底部留言。引用https://blog.daliansky.net/Lenovo-Tianyi-510s-Mini-and-macOS-BigSur-Installation-Tutorial.html https://github.com/daliansky/Lenovo-TianYi-510S-Mini-Hackintosh
-